La question portait sur le scénario APD et si la réponse à un APD devait être définie comme agressive ou conservatrice. C’est une bonne question et mon instinct me dit immédiatement : conservateur… Mais faut-il être configuré pour cela dans tous les cas ? Si oui, pourquoi diable avons-nous une méthode agressive ? Cela m’a fait réfléchir. (Au fait, assurez-vous de lire cet article de Matt Meyer sur VMCP sur le blog vSphere, bon article !) Mais avant de dévoiler la vérité, qu’est-ce qui est agressif/conservateur dans ce cas, et qu’est-ce que cette fonctionnalité déjà ?

La protection des composants VM (VMCP) est une nouveauté de la version 6.0 et permet à vSphere de répondre à un scénario dans lequel l’hôte a perdu l’accès à un périphérique de stockage. (PDL et APD.) Dans les versions précédentes, vSphere était déjà capable de répondre aux scénarios PDL, mais les paramètres n’étaient pas vraiment exposés dans l’interface utilisateur et cela a été fait avec la version 6.0 et la réponse APD a également été ajoutée en même temps. . Excellente fonctionnalité si vous me le demandez, en particulier dans les environnements étendus, car elle aidera lors de certains scénarios de panne.
Mais que se passe-t-il exactement lorsqu’une catastrophe survient et qu’un APD se produit ? Lorsqu’une condition APD est détectée, une minuterie est démarrée. Après 140 secondes, la condition APD est officiellement déclarée et l’appareil est marqué comme délai d’attente APD. (Notez que ceci est configurable, la valeur minimale pour Misc.APDTimeout est de 20 secondes.) Lorsque les 140 secondes se sont écoulées, HA commencera à compter, le délai d’expiration par défaut de HA est de 3 minutes. Une fois les 3 minutes écoulées, HA VMCP peut redémarrer les machines virtuelles impactées, en fonction de la façon dont vous l’avez configuré bien sûr. Vous pouvez définir trois réponses différentes :
- Désactivé
- Événements de problème
- Éteindre et redémarrer les machines virtuelles (conservateur)
- Éteindre et redémarrer les machines virtuelles (agressif)
Je pense que « handicapés » et « événements problématiques » parlent d’eux-mêmes, mais que signifient « conservateur » et « agressif » ? Conservateur et Agressif font référence à la probabilité que HA puisse redémarrer les machines virtuelles. Lorsqu’il est défini sur « conservateur », HA ne tuera la machine virtuelle affectée par l’APD que si elle sait qu’un autre hôte peut la redémarrer. Dans le cas d’une HA « agressive », elle tuera toujours la VM même si elle ne connaît pas l’état des autres hôtes, ce qui pourrait conduire à une situation dans laquelle votre VM ne redémarrera pas car aucun hôte n’a accès à la banque de données. la VM se trouve sur.
La question se pose alors : quand utilise-t-on conservateur et quand utilise-t-on agressif ? Eh bien, tout d’abord, permettez-moi de dire que «conservateur» est de loin l’approche la plus sûre et que pour les environnements «normaux» (non étendus), je recommanderais probablement toujours d’utiliser «conservateur», mais il existe bien sûr également des cas d’utilisation agressifs. . Je commencerais par poser ces questions en premier :
- Si vous utilisez un cluster étendu, s’agit-il d’une configuration « uniforme » ou « non uniforme » ?
- Quelle est la probabilité qu’un scénario APD se produise sur vos périphériques de stockage sur TOUS vos hôtes en même temps par rapport à certains hôtes ?
- Avez-vous configuré des règles VM to Host pour vos VM et quelle est la probabilité que les VM se trouvent du mauvais côté de la partition ?
Comme indiqué, je recommanderais probablement « conservateur » pour les environnements non étendus. Pour les étirés, les questions ci-dessus entrent en jeu. Pour les environnements « non uniformes », un APD est très rare, mais pour les environnements uniformes, il est plus courant. Ainsi, si vous disposez d’une configuration uniforme et qu’il est peu probable que l’APD se produise sur tous les hôtes de votre cluster (ce qui est généralement rare), la troisième question détermine comment configurer ce paramètre. Si vous avez configuré des règles VM vers hôte, il est peu probable qu’une VM réside du mauvais côté et, par conséquent, lorsqu’un APD se produit (partition de site par exemple), il est peu probable qu’une VM soit affectée car elle s’exécute du côté de l’hôte. cluster qui a une affinité avec la banque de données. Si vous n’avez pas configuré de règles VM/Hôte, les VM pourraient être partout et il serait préférable de configurer ce paramètre sur agressif afin que les VM soient supprimées instantanément et puissent être redémarrées sans risquer d’avoir 2 instances exécutées en même temps. temps. TU PEUX RÉPÉTER S’IL TE PLAIT? Oui, je réalise que c’est assez complexe, dessinons-le et décrivons-le étape par étape.
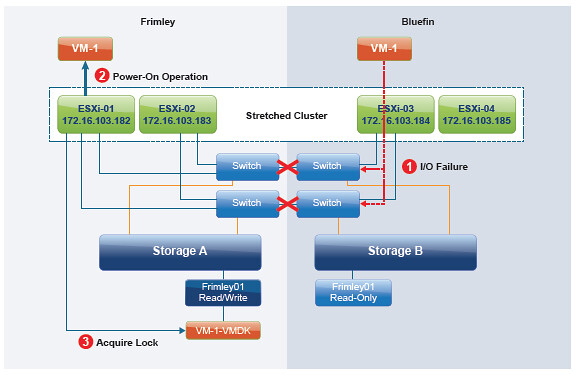
- Cet environnement utilise une configuration uniforme, ce qui signifie que TOUS les hôtes sont connectés à TOUS les systèmes de stockage.
- VM-1 s’exécute à l’emplacement « Bluefin », mais l’affinité de stockage est avec l’emplacement « Frimley »
- Une partition de site se produit et les hôtes de Bluefin perdent l’accès au « stockage A » et la banque de données « Frimley01 » se retrouve dans un état « APD » pour « ESXi-03 » et « ESXi-04 ».
- ESXi-01 et ESXi-02 ont toujours accès au stockage A et à la banque de données Frimley01 et redémarreront la VM-1
- Bien qu’ESXi-03 et ESXi-04 aient perdu l’accès à Frimley01, ils ne tueront VM-1 que lorsque :
- La protection des composants de la VM est configurée et la réponse APD est définie sur « agressive »
La raison en est que dans une partition complète, les hôtes des deux côtés ne peuvent pas communiquer entre eux et, par conséquent, ESXi-03 et ESXi-04 ne savent pas si ESXi-01 et ESXi-02 seront capables de redémarrer VM-1. Si la réponse APD est configurée sur « conservatrice », vous aurez alors une instance de VM-1 exécutée dans Frimley et une dans Bluefin. Celui de Bluefin n’aura bien sûr pas accès à la banque de données, ce qui empêche la corruption des données et d’autres mauvaises choses. Pourtant, avoir deux instances avec le même nom/adresse IP en cours d’exécution n’est jamais une bonne chose. Lorsque la réponse APD est définie comme agressive, cette situation peut être évitée.
Comme vous pouvez le constater, il s’agit d’un de ces paramètres qui n’a vraiment de sens que dans des scénarios très spécifiques et avec des configurations spécifiques. Alors avant de prendre une décision, réfléchissez bien !







Commentaires récents